Notes pour OCP 9i DBA1
Date de publication : 01/09/2004 ,
Date de mise a jour : 01/09/2004
8. Gestion des tables, index et contraintes
8.1. Création des tables
8.1.1. Gestion des LOB
8.1.2. Les tables partitionnées
8.1.3. Autres attributs de création de table
8.2. Modification des tables
8.3. Gestion des index
8.4. Les contraintes
8. Gestion des tables, index et contraintes
8.1. Création des tables
Oracle 9i supporte différents types de tables :
- Relationnelle. Ce sont les tables ordinaires. Elles sont du type par défaut ORGANIZATION HEAP.
- Temporaire : se créent par CREATE GLOBAL TEMPORARY TABLE
- IOT (tables organisées en index). Ce sont des tables qui sont prétriées dans l'ordre de la clé primaire. On les crée par CREATE TABLE ORGANIZATION INDEX.
- Externe. Ces tables sont en fait des fichiers plats stockés hors de la base. Ces pseudo-tables sont toujours en lecture seule, et sont lus par l'entremise de SQL*Loader. Il s'agit d'une nouveauté de la 9i. On les crée par CREATE TABLE ORGANIZATION EXTERNAL.
- Objet. Chaque ligne de la table représente un objet au sens POO.
Oracle supporte tout un ensemble de types de données prédéfinis, ainsi que des types définis par l'utilisateur.
Les types prédéfinis sont de 3 catégories : scalaire, collection et référence.
Les types scalaires sont les types simples (non composés), les types collection et référence ne servent que dans le contexte objet.
Notes sur quelques types scalaires
Les types CHAR et VARCHAR/VARCHAR2 admettent une option BYTE/CHAR, qui précise si la longueur est entendue comme nombre d'octets ou nombre de caractères.
La valeur par défaut de cette option dépend du paramètre NLS_LENGTH_SEMANTICS, elle est à BYTE par défaut.
La colonne CHAR_USED des vues xxx_TAB_COLUMNS indique pour chaque colonne l'interprétation de la longueur des chaînes, par B ou C.
Un type TIMESTAMP WITH TIMEZONE stocke un fuseau local, qui est visible par l'utilisateur. Un type TIMESTAMP WITH LOCAL TIMEZONE est automatiquemement converti dans le fuseau horaire du poste client; le fuseau horaire d'origine n'est pas visible.
Un BFILE stocke forcément les données à l'extérieur de la base.
Les collections peuvent être : des tableaux indexés, des tableaux variables (VARRAY) et des tables imbriquées.
Les références entre objets se spécifient par le mot REF.
La clause de stockage
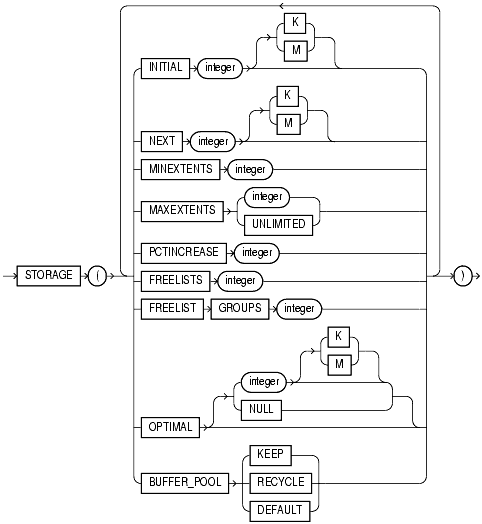
Les valeurs par défaut et valeurs minimales de ces différents paramètres sont les suivantes :
| paramètre |
Valeur par défaut |
Valeur minimale |
| INITIAL |
5 blocs |
mode manuel : 2 blocs + 1 par freelist group
mode auto : 5 blocs
|
| NEXT |
5 blocs |
1 bloc |
| MINEXTENTS |
1 extension |
1 extension (2 pour un segment de rollback) |
| MAXEXTENTS |
1 extension |
1 extension (2 pour un segment de rollback) |
| PCTINCREASE |
50% |
0 |
| FREELISTS |
1 |
1 |
| FREELIST GROUPS |
1 |
1 |
| OPTIMAL (RBS uniquement) |
|
|
Dans le cas d'une allocation UNIFORM d'un tablespace géré localement, la clause de stockage est ignorée.
FREELIST GROUPS s'utilise pour un tablespace géré par le dictionnaire. Il spécifie le nombre de listes de blocs libres. Chaque FREELIST GROUP occupe son propre bloc, c'est pourquoi la valeur INITIAL d'un segment doit faire au moins 2 blocs. Il est conseillé de donner à FREELIST GROUPS une valeur identique au nombre estimé de transactions concurrentes, et donc identique à INITRANS.
La clause BUFFER_POOL KEEP/RECYCLE/DEFAULT indique dans quelle partie du tampon de données doivent être placés les blocs lus du segment en question.
DEFAULT est le mode par défaut, où les blocs dans le tampon de données sont gérés par un algorithme LRU.
Le mode KEEP permet de maintenir en mémoire des blocs que l'on sait fréquemment utilisés.
8.1.1. Gestion des LOB
Un LOB est fondamentalement l'association d'un pointeur et d'une zone de données.
Une caractéristique importante des LOB, c'est qu'ils ne génèrent pas d'entrées dans les segments d'annulation. Les modifications sont donc permanentes, sans ROLLBACK possible.
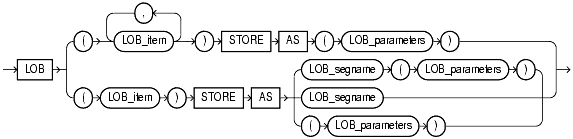
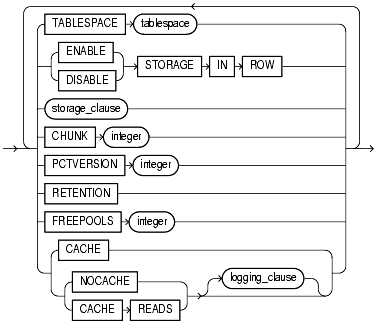
Les LOB peuvent faire l'objet d'une syntaxe spécifique et détaillée pour paramétrer leurs caractéristiques de stockage
LOB_parameters =
Exemple
CREATE TABLE print_media_new
( product_id NUMBER(6),
ad_sourcetext CLOB
ad_sourcetext CLOB )
LOB (ad_sourcetext, ad_finaltext) STORE AS
(TABLESPACE example
DISABLE STORAGE IN ROW
STORAGE (INITIAL 6144 NEXT 6144)
CHUNK 4000
PCTVERSION 20
NOCACHE LOGGING);
La partie LOB d'un enregistrement peut être stockée dans le même segment que les autres champs (stockage dit en ligne) ou dans un segment séparé (segment dit hors ligne).
Par défaut, si un LOB dépasse 4000 octets, il est stocké hors ligne. Le stockage en ligne/ hors ligne peut donc être différent d'une ligne à l'autre, puisque la taille d'un LOB ne peut être fixée à l'avance. C'est donc la taille réelle, au cas par cas, qui fait la différence.
La clause DISABLE/ENABLE STORAGE IN ROW spécifie si les LOB de moins de 4000 octets seront ou non stockés en ligne.
Le paramètre CHUNK spécifie la taille de l'unité de manipulation, car un LOB est manipulé par petits morceaux, et non en entier. CHUNK est toujours arrondi à un multiple de la taille de bloc.
Le paramètre PCTVERSION précise quel pourcentage du bloc doit être réservé pour assurer la lecture consistante. En effet, les LOB ne génèrent pas d'entrées d'annulation, et il faut donc un mécanisme spécifique.
Lors d'un CREATE AS SELECT, les contraintes ne sont pas transférées, sauf NOT NULL.
8.1.2. Les tables partitionnées
Le partitionnement consiste à subdiviser une table ou un index en plusieurs segments, qui sont accédés de manière autonome, et uniquement si nécessaire. Les performances d'accès aux très grandes tables peuvent donc être améliorées.
Chaque partition constituant un segment distinct, elle peut avoir un tablespace spécifique et sa propre clause de stockage.
Il existe 4 méthodes de partitionnement :
RANGE : on spécifie différents intervalles, chacun constituant une partition. Par exemple, on peut diviser la table des ventes selon la date, une partition par an. Les intervalles doivent être définis manuellement (borne inférieure de chaque partition)
CREATE TABLE range_sales
( prod_id NUMBER(6),
time_id DATE )
STORAGE (INITIAL 100M NEXT 100M)
PARTITION BY RANGE (time_id)
(PARTITION SALES_Q1_2000 VALUES LESS THAN ('01-APR-2000'),
PARTITION SALES_Q2_2000 VALUES LESS THAN ('01-JUL-2000'),
PARTITION SALES_Q3_2000 VALUES LESS THAN ('01-OCT-2000')
STORAGE (INITIAL 200M NEXT 200M),
PARTITION SALES_Q4_2000 VALUES LESS THAN (MAXVALUE));
On note que seule la 3ème partition a une clause de stockage spécifique définie. Les autres hériteront des paramètres définis au niveau de la table.
Les parenthèses autour des seuils de partition sont obligatoires.
Les valeurs nulles de la clé sont considérées comme supérieures à toutes les autres.
Si une valeur est hors des intervalles spécifiés, elle sera rejetée. Il faut donc utiliser la MAXVALUE pour être sûr que toutes les valeurs (y compris nulles) seront traitées.
HASH : quand on ne connaît pas la répartition des données, la méthode par hachage permet de les répartir à peu près équitablement. Il faut préciser sur quelle colonne le hachage doit s'effectuer. Il est conseillé de créer un nombre de partitions multiple de 2.
CREATE TABLE hash_products
( product_id NUMBER(6) ,
product_name VARCHAR2(50) )
PARTITION BY HASH (product_id)
PARTITIONS 5
STORE IN (tbs_1, tbs_2, tbs_3, tbs_4);
Cette commande définit un partitionnement par hachage sur la colonne "product_id", en créant 5 partitions qui seront stockées dans les tablespaces spécifiés. Comme il y a plus de partitions que de tablespaces listés, le premier tablespace servira aussi pour la partition 5.
LIST : on spécifie la liste des valeurs qui doivent appartenir à la même partition.
CREATE TABLE list_customers
( customer_id NUMBER(6),
nls_territory VARCHAR2(30))
PARTITION BY LIST (nls_territory)
( PARTITION asia VALUES ('CHINA', 'THAILAND'),
PARTITION europe VALUES ('GERMANY', 'ITALY', 'SWITZERLAND'),
PARTITION rest VALUES (DEFAULT));
COMPOSITE : cette méthode associe le partitionnement par intervalles (range) avec un sous-partitionnement par hachage ou par listes.
Concrètement, seules les sous-partitions ont une existence physique (un segment); les partitions ne sont qu'un niveau logique.
CREATE TABLE customers_part (
customer_id NUMBER(6),
cust_first_name VARCHAR2(20),
cust_last_name VARCHAR2(20),
nls_territory VARCHAR2(30),
credit_limit NUMBER(9,2))
PARTITION BY RANGE (credit_limit)
SUBPARTITION BY LIST (nls_territory)
SUBPARTITION TEMPLATE
(SUBPARTITION east VALUES
('CHINA', 'JAPAN', 'INDIA', 'THAILAND'),
SUBPARTITION west VALUES
('AMERICA', 'GERMANY', 'ITALY', 'SWITZERLAND'),
SUBPARTITION other VALUES (DEFAULT))
(PARTITION p1 VALUES LESS THAN (1000),
PARTITION p2 VALUES LESS THAN (2500),
PARTITION p3 VALUES LESS THAN (MAXVALUE));
Chaque partition est subdivisée selon le modèle de sous-partition (SUBPARTITION TEMPLATE).
8.1.3. Autres attributs de création de table
LOGGING/NOLOGGING : cet attribut spécifie si, lors d'un CREATE TABLE AS SELECT ou d'un chargement par le chemin direct, des entrées seront générés dans les fichiers de reprise. NOLOGGING est censé apporter un gain de performances, spécialement pour les index.
LOGGING est la valeur par défaut, à moins que le tablespace complet soit déclaré en mode NOLOGGING.
PARALLEL/NOPARALLEL spécifie si les instructions DML qui touchent la table peuvent ou non s'effectuer en parallèle. Les gains du parallélisme sont notables sur une machine multi-CPU, et dans un contexte décisionnel avec peu de concurrence. En environnement OLTP avec beaucoup de transactions concurrentes, le parallélisme n'est pas recommandé.
Le parallélisme ne peut pas s'appliquer sur des tables qui possèdent des déclencheurs ou des contraintes référentielles.
CACHE/NOCACHE : CACHE court-circuite l'algorithme LRU du tampon de données pour éviter la péremption des blocs. NOCACHE est la valeur par défaut, et convient la plupart du temps.
Ce paramètre a un effet comparable à l'attribut BUFFER_POOL KEEP.
La persistance des données dans une table temporaire se définit par la clause ON COMMIT DELETE ROWS / PRESERVE ROWS.
8.2. Modification des tables
Allocation et désallocation d'espace
On peut allouer manuellement une extension :
ALTER TABLE nom_table ALLOCATE EXTENT
(SIZE 1M DATAFILE 'h:\oracle\oradata\ora9\users.dbf');
La taille et le fichier cible sont facultatifs. Mais si le tablespace comporte plusieurs fichiers, on peut choisir le fichier cible. Ne pas oublier les parenthèses.
Le HWM mémorise la taille maximum jamais atteinte par un segment.
DBMS_SPACE.UNUSED_SPACE permet de connaître la valeur du HWM, par la soustraction de TOTAL_BYTES et de UNUSED_BYTES.
TRUNCATE remet à zéro le HWM, sauf si on spécifie REUSE STORAGE. Mais DELETE ne remet jamais le HWM à zéro, même si on vide la table complètement.
Quand un balayage de table complet est effectué, il va systématiquement au moins jusqu'au HWM, même pour une table vide !
Si un segment est trop grand, on peut le réduire, sans aller en-deçà du HWM.
Cette réduction s'effectue par
ALTER TABLE nom_table DEALLOCATE UNUSED KEEP n;
La clause facultative KEEP n spécifie qu'il faut conserver un espace de n Ko ou Mo au-delà du HWM. On ne fait donc qu'une libération partielle de l'espace inutilisé.
L'extension initiale du segment ne peut jamais être réduite, même si elle est largement surdimensionnée.
Si KEEP est utilisé, l'espace peut être réduit en deça de MINEXTENTS, et même de INITIAL, qui sont alors modifiés (tant qu'ils sont tous supérieurs au HWM).
Si KEEP n'est pas utilisé, MINEXTENTS et INITIAL sont maintenus, et seul l'espace supérieur peut être libéré.
Réorganisation de tables
Pendant longtemps, il fallait faire un export/DROP/import pour régénérer une table dans les paramètres de stockage n'étaient pas satisfaisants.
Depuis Oracle 8i, l'option MOVE permet de recréer une table ou un index, en modifiant tous ses paramètres de stockage, et en la plaçant si besoin dans un autre tablespace.
Cette opération peut se faire en mode NOLOGGING.
Les permissions en vigueur sur la table sont préservées par le MOVE.
Par exemple, la commande suivante transfère la table dans un nouveau tablespace.
ALTER TABLE nom_table MOVE TABLESPACE nom_tbs_cible;
Suppression d'une table
Lors de la suppression d'une table, les contraintes et permissions sont supprimées également, mais les vues, synonymes et programmes stockés qui y font référence ne sont pas supprimés. Ils sont seulement invalidés. En revanche, les déclencheurs définis sur la table sont supprimés.
TRUNCATE est considéré comme une instruction DDL, et non DML. Il effectue donc une validation implicite, et n'est pas annulable.
TRUNCATE n'active pas les déclencheurs, contrairement à DELETE.
Pour faire un TRUNCATE sur une table d'un autre schéma, il faut posséder le privilège DROP TABLE.
TRUNCATE préserve les contraintes et permissions.
Suppression de colonnes
On supprime une colonne par
ALTER TABLE nom_table DROP COLUMN nom_col;
ou
ALTER TABLE nom_table DROP (col1, col2, …);
Noter que le mot-clé COLUMN s'utilise pour une seule colonne à supprimer, et sans parenthèses.
La clause facultative CASCADE CONSTRAINTS est nécessaire uniquement si la colonne supprimée fait partie d'une contrainte multicolonne. Dans ce cas, la contrainte est supprimée.
Alternativement, on peut déclarer une colonne inutilisée (ou plusieurs) et la supprimer ultérieurement, pour ne pas surcharger le système.
ALTER TABLE nom_table SET UNUSED COLUMN nom_col;
ALTER TABLE nom_table SET UNUSED (col1, col2, …);
On supprimera ces colonnes désactivées plus tard, par
ALTER TABLE nom_table DROP UNUSED COLUMNS;
Toutes les colonnes désactivées de la table sont supprimées d'un coup, on ne peut pas spécifier leur nom.
L'analyse des tables
L'analyse permet de vérifier la bonne validité des blocs, et de calculer les statistiques sur les données.
La commande suivante valide la structure de la table, en faisant une lecture de chaque bloc.
ANALYZE TABLE nom_table VALIDATE STRUCTURE [CASCADE][INTO nom_table_cible];
La clause facultative CASCADE indique que les index liés à la table doivent être validés aussi.
Les erreurs éventuelles sont affichées à l'écran, mais ne sont enregistrées nulle part.
Pour les tables partitionnées uniquement, la clause facultative INTO indique dans quelle table doivent être stockés les résultats.
Par défaut VALIDATE STRUCTURE cherche à écrire les résultats dans la table INVALID_ROWS, qui peut être créée par le script utlvalid.sql, que l'on trouve dans le répertoire ORACLE_HOME\RDBMS\ADMIN.
Les enregistrements chaînés peuvent être détectés par la commande ANALYZE.
ANALYZE TABLE nom_table LIST CHAINED ROWS [INTO table_cible];
Par défaut, les resultants sont stockés dans la table CHAINED_ROWS, qui peut être créée grâce au script ORACLE_HOME\RDBMS\ADMIN\utlchain.sql.
Cette commande ne permet cependant pas de différencier les enregistrement chaînés (trop grands pour tenir dans un bloc) de ceux qui sont migrés (à cheval sur plusieurs blocs, mais qui pourraient tenir dans un seul).
Le commande ANALYZE permet aussi de générer des statistiques sur les tables et les index.
ANALYZE TABLE COMPUTE STATISTICS;
ANALYZE TABLE ESTIMATE STATISTICS SAMPLE n ROWS;
ANALYZE TABLE ESTIMATE STATISTICS SAMPLE n PERCENT;
L'option COMPUTE génère des statistiques en lisant la table complète.
L'option ESTIMATE ne lit qu'un échantillon des données, soit en nombre de lignes (1064 par défaut), ou en pourcentage.
Le calcul des statistiques par ANALYZE est considéré comme périmé, et doit être remplacé par l'usage de DBMS_STATS.
Structure d'un enregistrement
Chaque enregistrement possède une partie d'en tête (3 octets) et une partie de données.
Chaque colonne de l'enregistrement est précédée de sa longueur effective.
Les valeurs nulles sont représentées par une longueur de 0.
ROWID
Chaque enregistrement est identifié par son ROWID.
Il existe 2 types de ROWID : physique, pour les tables ordinaires, et logique, pour les IOT.
Un ROWID se présente sous la forme d'une chaîne de 18 caractères :
OOOOOFFFBBBBBBRRR, avec OOOOOO pour le numéro d'objet, FFF pour le numéro de fichier, BBBBBB pour le numéro de bloc, et RRR pour le numéro d'enregistrement dans le bloc.
Avant Oracle 8, le format des ROWID était dit restreint, il ne comportait pas le partie OOOOOO.
Si une conversion est nécessaire entre format étendu et format restreint, elle peut être faite grâce au paquetage DBMS_ROWID.
8.3. Gestion des index
Il existe différents types d'index.
Les index bitmap stockent une seule fois chaque valeur de la clé, et indiquent par un champ de bits si chaque ROWID contient ou non cette valeur.
Les index bitmap sont par définition non uniques, et sont utiles quand la clé de l'index a peu de valeurs différentes, comme pour le sexe (M ou F).
Les index bitmap stockent les valeurs nulles comme étant une valeur de clé. Dans ce cas, l'opérateur IS NULL pourra faire appel à l'index.
Les index b-tree sont structurés sous forme d'arbres équilibrés.
Ils peuvent être :
- unique, c'est à dire que chaque valeur de la clé n'apparaît qu'une fois
- non unique (option par défaut)
- à clé inversée. Cette option est utile quand les valeurs de l'index sont insérées en ordre croissant, ce qui conduirait à un arbre dégénéré, par manque de dispersion des valeurs. Le fait d'inverser les données octet par octet (54321, 64321, 74321 au lieu de 12345, 12346, 12347) améliore la dispersion des données, et donc les performances.
- basé sur une fonction, comme SUBSTR ou UPPER.
Tous les paramètres de la clause STORAGE qui peuvent être spécifies pour une table peuvent l'être aussi pour un index, hormis l'option PCTUSED.
En particulier, on peut spécifier une clause BUFFER_POOL KEEP pour un index.
La signification de PCTFREE est différente : elle correspond à l'espace réservé pour de futures valeurs de clé qui doivent s'intercaler dans les valeurs existantes.
Si les données de la table sont prétriées dans l'ordre du futur index, la création de l'index peut se faire avec l'option NOSORT, ce qui évite un tri.
Dans un index composite, la répétition des valeurs des premières colonnes peut être évitée par l'option COMPRESS. Cela économise l'espace, mais ralentit quelque peu les performances.
Les statistiques peuvent être calculées dès la création de l'index, par la clause COMPUTE STATISTICS ajoutée en fin de l'ordre CREATE INDEX.
Les index peuvent être partitionnés, indépendamment du partitionnement éventuel de leur table sous-jacente.
Si les partitions de l'index sont basées sur les mêmes critères que les partitions de la table sous-jacente, l'index est dit local, sinon il est global.
Les index partitionnés peuvent être préfixés ou non, c'est à dire que ses premières colonnes sont dans l'ordre des colonnes qui sont les critères de la partition.
On peut donc avoir des index partitionnés :
- Local prefixed
- Local non prefixed
- Global prefixed
- Global non prefixed
Les index bitmaps partitionnés ne peuvent être créés que sur des tables elles-mêmes partitionnées, et les critères de partitionnement doivent être identiques entre l'index et la table. Les index bitmap partitionnés sont donc forcément locaux.
Un index à clé inversée se crée comme suit (le mot clé REVERSE se place à la fin) :
CREATE INDEX i ON t (a,b,c) REVERSE;
Les index fonctionnels peuvent être de type bitmap ou de type b-arbre.
Ils doivent remplir de multiples conditions pour être utilisés :
- des statistiques doivent impérativement avoir été calculées
- le paramètre d'initialisation QUERY_REWRITE_ENABLED doit être à TRUE
- le paramètre d'initialisation QUERY_REWRITE_INTEGRITY doit être à TRUSTED
Les IOT
Les tables organisées en index contiennent dans le même segment l'index et la table. Autrement dit, toutes les colonnes de la table sont stockées dans l'index (mais toutes ne servent pas de clé pour autant).
La notion de ROWID ne s'applique pas classiquement aux IOT.
Un IOT étant fondamentalement une table, d'autres index peuvent être créés sur les IOT.
Un IOT se spécifie par la clause ORGANIZATION INDEX du CREATE TABLE.
Un index peut être désactivé sans le supprimer pour autant :
ALTER INDEX nom_index UNUSABLE;
Pour le réactiver, il faut ensuite le régénérer. La régénération effectue de manière transparente une recréation suivie d'une suppression.
ALTER INDEX nom_index REBUILD;
REBUILD est l'équivalent pour les index du MOVE pour les tables. Il permet de déplacer un index, ou de modifier ses paramètres de stockage.
Pour renommer un index, utiliser
ALTER INDEX RENAME ancien_nom TO nouveau_nom;
Pour défragmenter un index, utiliser
ALTER INDEX nom_index COALESCE;
Il n'est pas possible de supprimer les index liés à une contrainte d'unicité ou de clé primaire. Pour cela, il faut désactiver la contrainte en question, ce qui suffit à supprimer l'index.
Les index peuvent être analysés tout comme les tables grâce à la commande ANALYZE INDEX. (Cependant, il n'existe pas d'option LIST CHAINED ROWS pour les index)
Pour savoir si un index est utile, on peut tracer basiquement son utilisation.
ALTER INDEX nom_index MONITORING USAGE;
Les résultats sont visibles dans la vue V$OBJECT_USAGE. On y voit si l'index est monitoré, et s'il est utilisé (sous forme OUI/NON, cette information n'est pas très raffinée).
La vue DBA_IND_COLUMNS liste les colonnes constitutives des index. (C'est l'équivalent de DBA_TAB_COLUMNS)
La vue INDEX_STATS stocke le résultat de ALTER INDEX VALIDATE STRUCTURE;
8.4. Les contraintes
Les contraintes peuvent être de 5 types : NOT NULL, PRIMARY KEY, FOREIGN KEY, CHECK, UNIQUE.
Les contraintes NOT NULL peuvent être spécifiées uniquement au niveau de la colonne, et non au niveau de la table.
Pour passer une colonne de NULL à NOT NULL ou vice versa :
ALTER TABLE nom_table MODIFY nom_colonne NULL/NOT NULL;
Noter que le mot-clé est MODIFY, car on modifie la colonne, et non la contrainte.
Si la contrainte NOT NULL est nommée, on peut faire
ALTER TABLE nom_table DISABLE CONSTRAINT NN_contrainte;
ce qui a le même effet que le MODIFY ci-dessus.
Dans une contrainte CHECK, aucune pseudo-colonne, séquence ou fonction d'environnement comme SYSDATE ou SYS_CONTEXT n'est utilisable.
Une colonne avec un contrainte UNIQUE accepte néanmoins les valeurs nulles.
Pour les contraintes UNIQUE et PRIMARY KEY, qui provoquent la création automatique d'un index, on peut spécifier le tablespace de destination et la clause de stockage de cet index, grâce à la clause USING INDEX.
CREATE TABLE test (a INT CONSTRAINT PK_COL1 PRIMARY KEY USING INDEX TABLESPACE indx STORAGE(INITIAL 10K NEXT 20K));
Il en est de même lorsqu'on active une telle contrainte : l'index est recréé, et on peut spécifier ses paramètres.
Lors de la création d'une contrainte UNIQUE ou PRIMARY KEY, on peut utiliser la clause EXCEPTIONS INTO, qui répertorie les lignes qui violent la contrainte.
ALTER TABLE nom_table ADD CONSTRAINT nom_contrainte UNIQUE(col) EXCEPTIONS INTO EXCEPTIONS;
La table cible s'appelle en principe EXCEPTIONS (elle aussi !), et peut être créée par le script %ORACLE_HOME%\RDBMS\ADMIN\utlexcpt.sql.
Une contrainte peut être désactivée à sa création :
ALTER TABLE nom_table ADD CONSTRAINT nom_contrainte CHECK (BONUS >0) DISABLE;
L'activation/désactivation d'une contrainte peut se faire selon 2 syntaxes. Suivant l'utilisation ou nom du mot MODIFY, ENABLE/DISABLE n'est pas placé au même endroit.
ALTER TABLE nom_table MODIFY CONSTRAINT nom_contrainte ENABLE/DISABLE;
ALTER TABLE nom_table ENABLE/DISABLE CONSTRAINT nom_contrainte;
Pour désactiver une clé primaire qui est référencée par des clés étrangères, il faut utiliser la clause CASCADE, qui a pour effet de désactiver les contraintes de clé étrangères qui posent problème (mais ne supprime rien !)
ALTER TABLE nom_table DISABLE PRIMARY KEY CASCADE;
Les clauses ENABLE/DISABLE d'une contrainte peuvent être suivies par VALIDATE/NOVALIDATE.
ENABLE VALIDATE vérifie les données existantes à l'activation de la contrainte. C'est le comportement par défaut de ENABLE.
ENABLE NOVALIDATE ne vérifie pas les données existantes. Cela peut être intéressant sur de grosses tables, si on est sûr de leur cohérence.
DISABLE VALIDATE désactive la contrainte, mais interdit toute insertion ou modification dans la table. C'est une manière d'empêcher les écritures.
DISABLE NOVALIDATE désactive simplement la contrainte. C'est le comportement par défaut de DISABLE.
Par défaut, les contraintes sont vérifiées à la fin de l'instruction (INSERT, UPDATE, DELETE, MERGE).
Dans certains cas, on souhaite que la vérification se fasse à la fin de la transaction, ce qui permet par exemple de remplir une table fille avant sa table mère.
Pour cela, la contrainte doit avoir été créé comme DEFERRABLE. (Si cela a été oublié, il faut recréer la contrainte).
CREATE TABLE test (col1 int CONSTRAINT unic UNIQUE DEFERRABLE INITIALLY DEFERRED);
La clause facultative INITIALLY DEFERRED ou INITIALLY IMMEDIATE précise en outre si la contrainte sera vérifiée en fin de transaction ou en fin d'instruction DML.
La commande SET CONSTRAINT nom_contrainte indique si, pour la transaction en cours, la vérification sera reportée ou immédiate. Le comportement général peut être défini par ALTER SESSION : ALTER SESSION SET CONSTRAINTS=DEFERRED
|